目次
とある日
LambdaとAPI Gatewayを使って開発してたときの備忘録。
書いてるとそこそこ長かったのでLambdaとAPIGatewayに分けて記事にします。
職場の環境で作成していたので、この記事では実際のコードや画面をお見せすることはできません。
基本的に文章ベースで記述します。
LambdaやAPI Gatewayでハマったポイントをまとめてるのでこれから作成する人は気をつけてください。
参考にした記事などもあるのでご参考までに。
それとこの開発は、2021年6月3日頃の仕様に基づいて作成しています。
AWS構成図
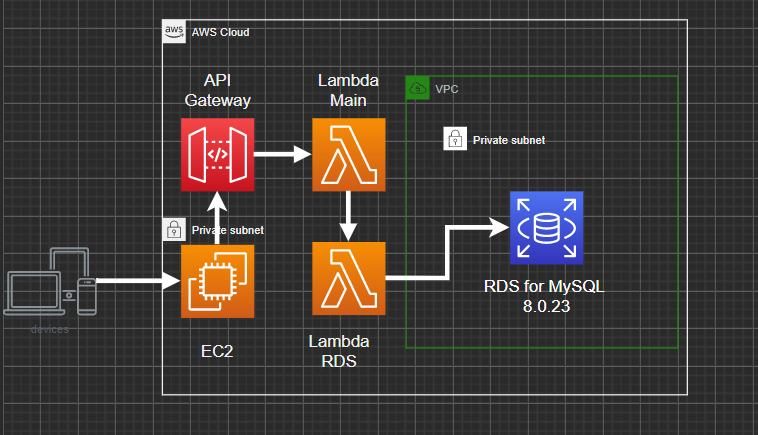
サービス説明
EC2
HTMLやCSS,JavaScriptなど静的サイト
-
EC2からのAPIアクセスのエンドポイント
Lambda
RDS
コンテンツを格納
簡単なサイトを構築している。
サイトで必要な情報はデータベースに格納している。
サービス活用経緯
Lambda
サーバーやクラスターについて検討することなくコードを実行できます。料金は従量課金制です。
AWSでサーバレスの代表とも言えるサービスで、PythonやNode.jsでアプリケーションを開発することができる。
今回は、Python3.8を使用して開発を行いました。
API Gatewayで呼ばれたAPIごとの処理を行いました。
Lambdaで行った処理
RDS TIMESTAMP処理
RDS for MySQLでTIMESTAMP型を扱うデータを取得した際に起こった出来事のお話です。
※MySQLのTIMESTAMP型はPythonだとdatetime型となります。
pymysqlというライブラリーを使用してMySQLに接続後、SELECT文を発行してデータをそのままreturnしたときに下記のエラーが出力された。
TypeError: Object of type 'datetime' is not JSON serializable
以前の別の開発でも起こった事象なので、原因究明は簡単でした。
ただここからが問題です。
以前の解決方法は参照記事と同じようにjson.dumps関数の引数にオプションをつけるだけで解決するはずなのですが!
json.dumps()
json.``dumps(obj, , skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, kw*)この 変換表 を使って、obj を JSON 形式の
strオブジェクトに直列化します。引数はdump()と同じ意味です。
json --- JSON エンコーダおよびデコーダ — Python 3.9.4 ドキュメント
Lambdaは、その処理を裏側で行っているので手がさせない!!
もっと具体的いうと、
Python の Lambda 関数ハンドラー - AWS Lambda
def lambda_handler(event, context): message = 'Hello {} {}!'.format(event['first_name'], event['last_name']) return { 'message' : message }
3行目でreturnしたあとにLambdaが json.dumps関数の処理を行ってクライアント側にレスポンスを返していると思われます。
なので解決方法として考えたのが下記2パターン
- returnする前に json.dumps関数で処理を行う
- datetimeオブジェクトを一つ一つ文字列に変換する
自分は、前者を行いました。
ただ、前者を選ぶとクライアント側でも処理が発生します。
クライアント側のJavaScriptでレスポンスデータをJSON.parse()で変換を行う必要があります。
なぜ、前者を選択したかについては、Lambdaだとデバックがしづらい環境のため手っ取り早い解決を行いたかったため。
pymysqlが列ごとで配列の取得等ができたらもっと楽なのでやるのですが、
そこそこに工数がかかると考えました。
別Lambdaを呼び出す
実際のPythonの開発なら別ファイルなどimportするのは簡単なのですが、
Lambdaでは、別Lambda関数として定義して呼び出すとなると少しめんどくさいです。
やり方は下記の記事を参考にすればできると思います。
ここでは何がめんどくさいのかと、なぜLambdaを分けて開発したのかについて話します。
めんどくさいと思った理由
結論としては、処理やデバックが段階的にしかできないため値の受け渡し等がやりづらいためです。
- Lambda Main
- Lambda Main→Lambda RDS
- Lambda Main→Lambda RDS→RDS
この三段階でテストする必要があるからです。
処理が分割できることは処理の切り分けの観点から言いと思うのですが、
処理分割しすぎると逆に管理が煩雑になるといったデメリットが発生します。
Lambdaを分割した理由
疎結合での開発と、処理の切り分けのため分割を行おうと考えました。
AWSでも疎結合の考えがありますが、プログラミング言語にも存在します。
データベース(DB)関係のプログラムは、様々な処理から呼ばれるので柔軟に対応できるようにDB接続部分、SQL実行部分、トランザクション管理部分など関数を切り分けるほうが柔軟に対応できます。
そのため今回の開発では、MainのAPI処理とDB関係の処理を行う2つのLambda関数を作成しました。
デバック
前提として、PythonでのデバックはLambdaのテスト画面でprint関数を使用して行っていました。
これからLambdaを使う方は、正しいデバックを行うほうが良いと思います。
AWS Lambda/PythonでJSON形式でログを出すベストプラクティス - Qiita
Lambdaのログ出力にオススメしたいPythonのライブラリLambda Powertools | DevelopersIO
リクエストパラメータ
どこに、フロントからのリクエストパラメータや本文が格納されているかがわからなかった。
自分で、テストを作成すると自由にリクエストパラメータを変更できることを知った。
使い始めは、どこに何の機能があるかわからず苦戦した。
deploy保存時間
Lambdaのコードを修正したら、デプロイを押すと思うのですが。
コードを修正してからデプロイを押すまでの時間が早すぎると、修正されていない判定になるので。
エラーになります。ほぼ確実に。なぜなら途中までしか記述できていないから。
何回か途中までの修正の状態でデプロイを押しました。
1秒ぐらいまってからデプロイをしましょう。
出力ログ制限
CloudWatchなどでログを確認するのが適切な気がしますが、
めんどくさいのとLambda上でもすぐ確認できるのでLambdaで確認していたところ。
Function Logsが、print関数などで出力が表示される項目なのですが、
あまり多い出力だと前半分が表示されません。
例)想定:print関数で出力した場合 (イメージ図)
print("abcdefghijklmnopqrstuvwsyz") Function Logs abcdefghijklmnopqrstuvwsyz
例)ログが多い場合:print関数で出力した場合 (イメージ図)
print("abcdefghijklmnopqrstuvwsyz") Function Logs lmnopqrstuvwsyz
上記の例のように前半の「abcdefghijk」の部分が排除されています。
どの量のログかは定かではないですが、前半のログがなく後半のログだけ残る現状に遭遇しました。
なので、必要なログだけに絞って出力することをおすすめします。
〆
なかなかに構築は大変でした。
開発の環境を構築しないという従来の手間は省けますが、
Lambda特有の現象ややり方に慣れる必要がある上に、他サービスとの連携となると難易度は高くなる印象です。